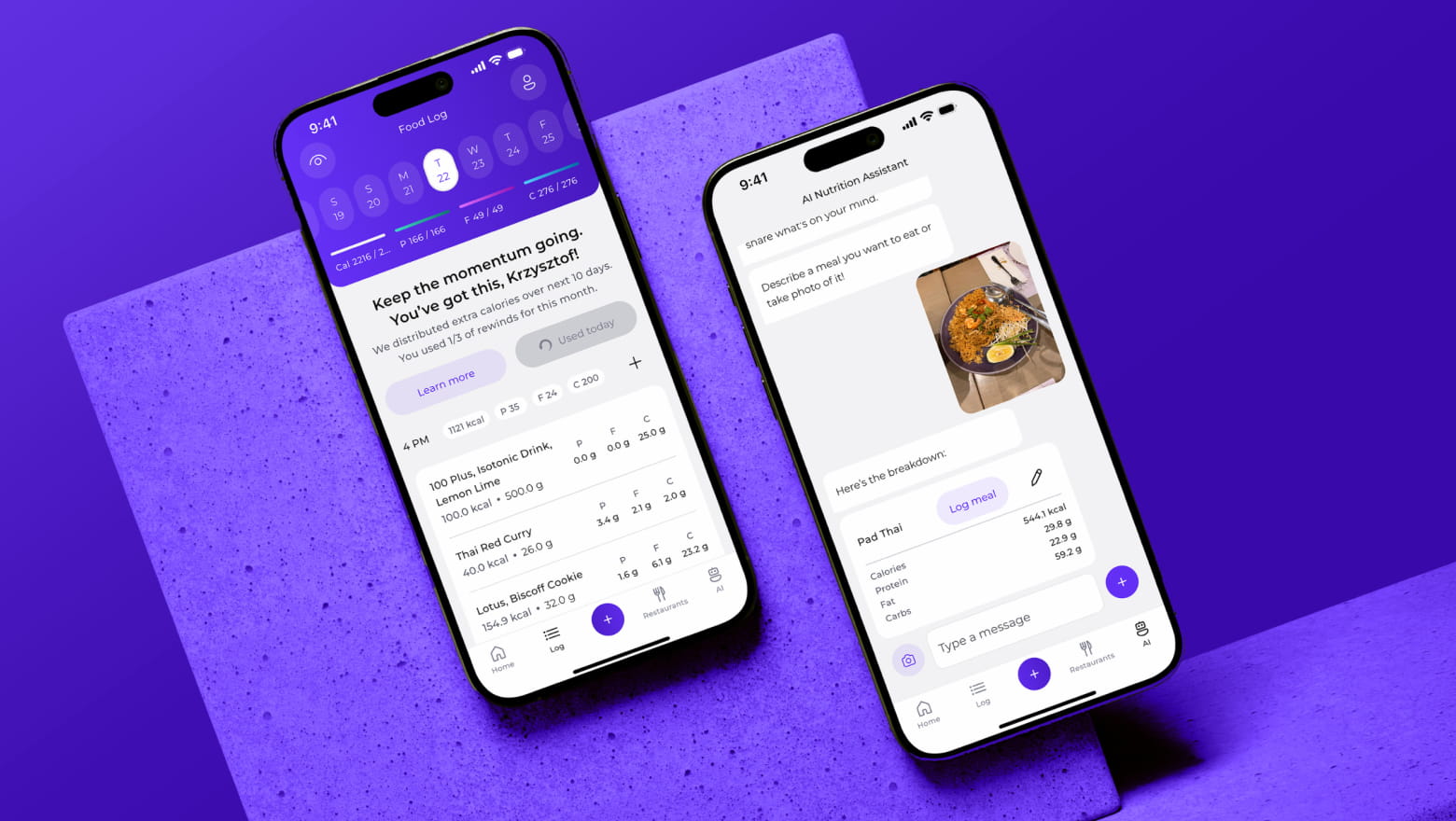
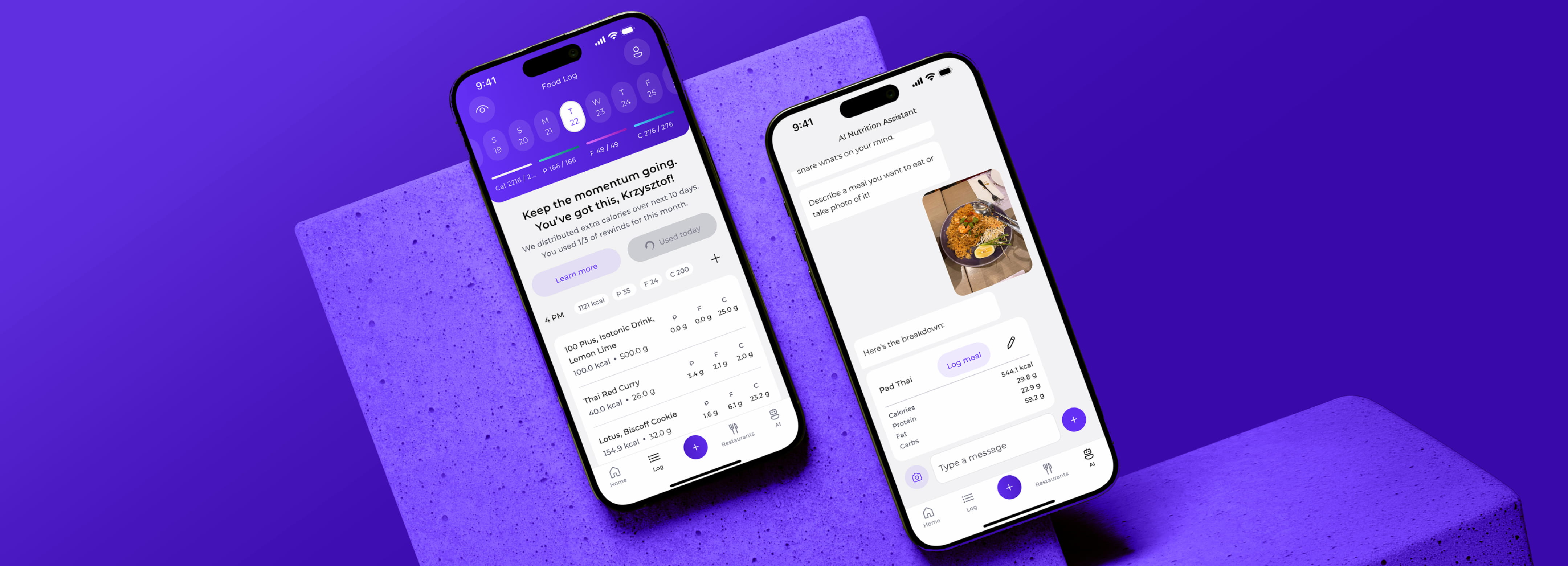
When working with a dedicated AI
mobile app development company, building a foundational model from scratch is rarely cost-effective unless you are operating in a highly niche domain with proprietary data parameters. Instead, engineering reality points toward optimization. We typically select high-performing, pre-trained open-source models (such as variants of Llama, Mistral, or Phi) or platform-native models (like Google Nano). As an AI-powered mobile app development company, we then apply fine-tuning, Low-Rank Adaptation (LoRA), and strict weight quantization to fit that model to your specific domain logic and device constraints.